How Fast a Bufferedreader Reader Read File

How to Read Files Easily and Fast [Java Files Tutorial, Role i]

past Sven Woltmann – November 21, 2019
The packages This article series starts by introducing simple utility methods for reading and writing files. Later articles volition comprehend more than circuitous and advanced methods: from channels and buffers to memory-mapped I/O (it doesn't thing if that doesn't tell you anything at this point). The first article covers reading files. First, you learn how to read files that fit entirely into memory: Later that we go on to larger files and the respective classes: Besides (and this applies to both small-scale and large files): Upwards to and including Java half dozen, you had to write several lines of plan code around a Merely tertiary-political party libraries (e.one thousand., Apache Eatables or Guava) provided more convenient options. With Java seven, JSR 203 brought the long-awaited "NIO.2 File API" (NIO stands for New I/O). Among other things, the new API introduced the utility class You'll notice out in the following sections what these methods are in particular. Yous can read the complete contents of a file into a byte array using the The class If you want to load the contents of a text file into a String, use – since Coffee 11 – the The method In most cases, text files consist of multiple lines. If you want to process the text line past line, yous don't have to bother splitting upwardly the imported text by yourself. That is done automatically when reading the file using the Then you tin iterate over the received string list to process it. Java 8 introduced streams. Correspondingly, in the aforementioned Java version, the For instance, with merely ane code argument, y'all could output all lines of a text file that comprise the Cord "foo": The four methods shown to a higher place embrace many utilise cases. Even so, the files read should non be as well large, since they are loaded completely into RAM. Then you shouldn't try that with an HD movie. Just also for smaller files, there are proficient reasons not to load them completely into RAM: The following affiliate describes how you tin read files slice by piece and process them at the same fourth dimension. This question takes usa to the classes and methods that were already available before Java seven – those that made "permit's chop-chop read a file" a complicated matter. In the simplest example, nosotros read a binary file byte by byte and then process these bytes. The The This access is relatively expensive: Loading a test file of 100 one thousand thousand bytes via With the NIO.2 File API in Coffee vii, a second method to create an This method returns a You tin can accelerate reading the data with This code reads the aforementioned file in merely 270 ms, which is 700 times faster. That is 370 MB per second, an first-class value. Y'all should almost e'er use Later all, text files are binary files, too. When being loaded, an It's a bit more than comfortable with Although Using a Another advantage of Reading consummate lines further reduces the total time for reading the test file to about 600 ms. With The speed corresponds to the speed of the "classically" created The following diagram shows all the methods presented, including the fourth dimension they need to read a file of 100 million bytes: The large gap between "unbuffered" and "buffered" leads to the fact that the "buffered" methods are hardly recognizable in the diagram above. Therefore, beneath is a second diagram that shows simply the buffered methods: The last sections introduced numerous classes for reading files from the The solid lines correspond the flow of binary data; the dashed lines bear witness the menstruation of text data, i.e., characters and strings. In the concluding chapter, we read text files without any worries. Unfortunately, it'southward not e'er that easy: grapheme encodings, line breaks, and path separators brand life difficult even for experienced programmers. As long as you only deal with English texts, you may have got around the problem. If you also work with texts in other languages, you probably have seen something similar this at some point (the example is a German language Pangramm): Or something like this? Those strange characters are the effect of unlike grapheme encodings beingness applied for reading and writing a file. When I introduced the A brief history of graphic symbol encodings For historical reasons, various character encodings exist. The start character encoding, ASCII, was standardized in 1963. Initially, ASCII could stand for only 128 characters and control characters. Neither did information technology include German language umlauts nor not-Latin messages such every bit Cyrillic or Greek ones. Therefore, ISO-8859 introduced fifteen additional graphic symbol encodings, each containing 256 characters, for various purposes. For example, ISO-8859-ane for Western European languages, ISO-8859-5 for Cyrillic or ISO-8859-7 for Greek. Microsoft slightly modified ISO-8859-1 for Windows and created its custom encoding, Windows-1252. To eliminate this chaos, Unicode, a globally uniform standard, was created in 1991. Currently (as of Nov 2019), Unicode contains 137,994 different characters. A single byte can represent a maximum of 256 characters. Therefore, unlike encodings were developed to map all Unicode characters to 1 or more than bytes. The most widely used encoding is UTF-8. Currently, 94.iv% of all websites utilize UTF-8 (according to the previously linked Wikipedia page). UTF-8 uses the same bytes equally ASCII to represent the get-go 128 characters (e.m., 'A' to 'Z', 'a' to 'z', and '0' to '9'). That is the reason why these characters are always readable – even if the encoding is set incorrectly. UTF-8 represents German umlauts by two bytes each. Therefore, in the beginning example above (in which I saved the text as UTF-8 so loaded it as ISO-8559-1), there are two special characters at the places of the umlauts. In the second instance, I saved the text every bit ISO-8859-1 and loaded it as UTF-8. Since the ane-byte representation of the umlauts from ISO-8859-one makes no sense in UTF-viii, the InputStreamReader inserted question marks at the corresponding places. Therefore, always make sure to use the aforementioned character when reading and writing a file. If no grapheme encoding is specified (as in the previous examples), a standard encoding is applied. And now it gets unsafe: The encoding can exist different depending on which Java version and which method is used to read the file: To be on the condom side, you should e'er specify a graphic symbol encoding. If possible (i.e. if no compatibility with old files needs to be guaranteed) you should use the almost mutual encoding, UTF-8. All methods presented and then far offer a variant in which you lot tin can explicitly specify the grapheme encoding. Y'all need to laissez passer it as an object of the Some other obstacle when loading text files is the fact that line breaks are encoded differently on Windows than on Linux and Mac OS. Fortunately, most programs today tin handle both encodings. Information technology was non ever like this. In the past, when people exchanged text files between dissimilar operating systems, either all line breaks disappeared, and the entire text was in one line, or special characters appeared at the end of each line. When you read a text file line by line with When writing files (see the article "How to write files quickly and easily"), I recommend using the Linux version because, nowadays, almost every Windows program (since 2018, fifty-fifty Notepad!) tin handle information technology. When creating a formatted string with You lot tin can try it with the post-obit plan: On Linux and Mac OS, the output is 6 and 6. On Windows, however, it is 7 and half-dozen, since the line suspension generated with "%n" consists of one more than character. If yous demand the line separator of the current arrangement, you can go information technology through Also, with path names, nosotros must consider differences between the operating systems. While on Windows, absolute paths begin with a drive letter and a colon (e.g. "C:") and directories are separated by a backslash ('\'), on Linux they are separated past a forward slash ('/'), which as well indicates the beginning of accented paths. For example, the path to my Maven configuration file is: You can access the separator used in the current operating system via the Y'all unremarkably should non need the separator direct. Coffee provides the classes At this point, I am not going into further detail. File and directory names, relative and absolute path information, old API, and NIO.2 render the topic quite circuitous. I volition, therefore, cover the topic in a separate article. In this article, nosotros take explored various methods of reading text and binary files in Java. We also looked at what you demand to consider if you want your software to run on operating systems other than your own. In the 2d function, you lot will learn about the corresponding methods for writing files in Java. Subsequently, nosotros'll discuss the post-obit topics: And at the end of the serial, we volition plow to advanced topics: If yous want to be informed when the second part is published, please click here to sign upwardly for the HappyCoders newsletter. the post-obit form. And I would also exist happy if you share the article using one of the buttons below.java.io and java.nio.file contain numerous classes for reading and writing files in Coffee. Since the introduction of the Java NIO.2 (New I/O) File API, it is easy to get lost – non just as a beginner. Since so, you tin perform many file operations in several ways.
FileReader, FileInputStream, InputStreamReader, BufferedInputStream und BufferedReader?Files.newInputStream() and Files.newBufferedReader()?
What is the easiest manner to read a file in Java?
FileInputStream to read a file. You had to make sure that yous shut the stream correctly after reading – also in case of an error. "Try-with-resource" (i.east., the automatic closing of all resources opened in the try block) did not exist at that time. coffee.nio.file.Files, through which y'all tin read entire text and binary files with a single method call. Reading a binary file into a byte array
Files.readAllBytes() method: String fileName = ...; byte[] bytes = Files.readAllBytes(Path.of(fileName)); Path is an abstraction of file and directory names, the details of which are not relevant here. I will go into this in more than detail in a hereafter article. First of all, it is enough to know that you tin create a Path object via Paths.get() or – since Java 11 a scrap more than elegantly – via Path.of(). Reading a text file into a string
Files.readString() method as follows:
Cord fileName = ...; String text = Files.readString(Path.of(fileName)); readString() internally calls readAllBytes() and then converts the binary data into the requested String. Reading a text file into a String list, line by line
readAllLines() method available since Java 8:
String fileName = ...; List<String> lines = Files.readAllLines(Path.of(fileName)); Reading a text file into a String stream, line by line
Files class was extended past the method lines(), which returns the lines of a text file not as a String list, but as a stream of Strings: Cord fileName = ...; Stream<String> lines = Files.lines(Path.of(fileName)); Files.lines(Path.of(fileName)) .filter(line -> line.contains("foo")) .forEach(System.out::println); java.nio.file.Files – Summary
How to process large files without keeping them entirely in retentivity?
Reading large binary files with FileInputStream
FileInputStream class performs this task. In the following instance, it is used to output the contents of a file to the console byte past byte. String fileName = ... ; try (FileInputStream is = new FileInputStream(fileName)) { int b; while ((b = is.read()) != -ane) { Organization.out.println("Byte: " + b); } } FileInputStream.read() method reads one byte at a time from the file. When information technology reaches the end of the file, it returns -i. Well-nigh of the functionality of this course is implemented natively (i.due east., not in Java), since information technology directly accesses the I/O functionality of the operating system. FileInputStream takes about 190 seconds on my system. That's only virtually 0.five MB per second. Reading big binary files with the NIO.two InputStream
InputStream, Files.newInputStream(), was introduced: String fileName = ...; try (InputStream is = Files.newInputStream(Path.of(fileName))) { int b; while ((b = is.read()) != -ane) { Organization.out.println("Byte: " + b); } } ChannelInputStream instead of a FileInputStream because NIO.2 works with and then-called channels nether the hood. This difference doesn't impact the speed in my tests. Reading faster with BufferedInputStream
BufferedInputStream. It is placed around a FileInputStream and loads data from the operating arrangement not byte by byte, but in blocks of 8 KB and stores them in memory. The bytes can and so be read out again chip past bit – and from the main retention, which is much faster. String fileName = ...; try (FileInputStream is = new FileInputStream(fileName); BufferedInputStream bis = new BufferedInputStream(is)) { int b; while ((b = bis.read()) != -1) { System.out.println("Byte: " + b); } } BufferedInputStream. The simply exception is if you do not read data byte by byte, only in larger blocks whose size is adjusted to the cake size of the file organization. If you are unsure whether BufferedInputStream is worthwhile for your particular application, try it out. Reading large text files with FileReader
InputStreamReader can be used to convert their bytes into characters. Place it around a FileInputStream, and you can read characters instead of bytes: String fileName = ...; effort (FileInputStream is = new FileInputStream(fileName); InputStreamReader reader = new InputStreamReader(is)) { int c; while ((c = reader.read()) != -1) { System.out.println("Char: " + (char) c); } } FileReader: It combines FileInputStream and InputStreamReader, resulting in the following code, which is equivalent to the one higher up: String fileName = ...; endeavor (FileReader reader = new FileReader(fileName)) { int c; while ((c = reader.read()) != -i) { System.out.println("Char: " + (char) c); } } InputStreamReader also uses an internal eight KB buffer. Reading the 100 million byte text file graphic symbol by character takes virtually 3.8 due south. Read text files faster with BufferedReader
InputStreamReader is already quite fast, reading a text file tin can be further accelerated – with BufferedReader: String fileName = ...; try (FileReader reader = new FileReader(fileName); BufferedReader bufferedReader = new BufferedReader((reader))) { int c; while ((c = bufferedReader.read()) != -1) { Arrangement.out.println("Char: " + (char) c); } } BufferedReader reduces the time for reading the test file to virtually 1.three seconds. BufferedReader achieves this past extending the InputStreamReader's eight KB buffer with another buffer for viii,192 decoded characters.BufferedReader is that it offers the additional method readLine(), which allows you lot to read and process the text file not only character by character but also line past line: String fileName = ...; try (FileReader reader = new FileReader(fileName); BufferedReader bufferedReader = new BufferedReader((reader))) { String line; while ((line = bufferedReader.readLine()) != null) { System.out.println("Line: " + line); } } Reading text files faster with the NIO.2 BufferedReader
Files.newBufferedReader(), the NIO.2 File API provides a method to create a BufferedReader directly: String fileName = ...; effort (BufferedReader reader = Files.newBufferedReader(Path.of(fileName))) { int c; while ((c = reader.read()) != -ane) { System.out.println("Char: " + (char) c); } } BufferedReader and also needs about 1.3 seconds to read the entire file. Overview performance
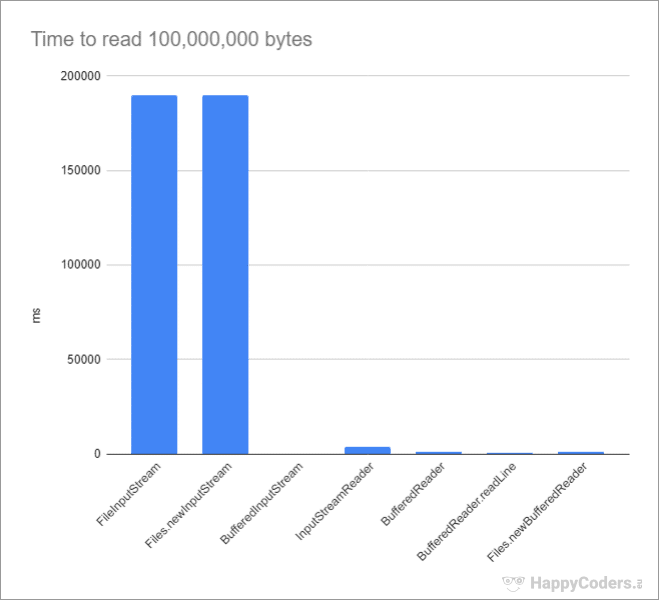

Overview FileInputStream, FileReader, InputStreamReader, BufferedInputStream, BufferedReader
java.io package. The following diagram shows, once again, the relationships of these classes. If this topic is new to you, it helps to accept a look at it from fourth dimension to fourth dimension.
FileReader is a combination of FileInputStream and InputStreamReader. Operating organisation independence
Character encoding


InputStreamReader course, I briefly mentioned that it converts bytes (numbers) into characters (such as letters and special characters). The and then-called grapheme encoding determines which character is encoded by which number. What grapheme encoding does Coffee apply by default to read text files?
FileReader or InputStreamReader, the method StreamDecoder.forInputStreamReader() is called internally, which uses Charset.defaultCharset() if the graphic symbol encoding is not specified. This method reads the encoding from the system property "file.encoding". If you haven't specified that either, it uses ISO-8859-1 until Java 5, and UTF-8 since Coffee half-dozen.Files.readString(), Files.readAllLines(), Files.lines() or Files.newBufferedReader() without grapheme encoding, UTF-8 is used directly, without checking the system holding mentioned above. How to specify the grapheme encoding when reading a text file?
Charset class. You can detect constants for standard encodings in the StandardCharsets class. In the post-obit, yous find all methods with the explicit specification of UTF-8 equally encoding:
Files.readString(path, StandardCharsets. UTF_8 ) Files.readAllLines(path, StandardCharsets. UTF_8 ) Files.lines(path, StandardCharsets. UTF_8 ) new FileReader(file, StandardCharsets. UTF_8 ) // this method just exists since Java 11 new InputStreamReader(is, StandardCharsets. UTF_8 ) Files.newBufferedReader(path, StandardCharsets. UTF_8 ) Line breaks
0A).0D0A). Files.readAllLines() or Files.lines(), Java automatically recognizes the line breaks correctly. If you want to split a text into lines in your programme code, y'all can utilise String.split() as follows: String[] lines = text.dissever("r?northward"); Cord.format(), you need to pay attention to how you specify the line pause:
String.format("Hallo%n") inserts an operating arrangement specific line break. The result differs depending on the operating system on which your program is running.String.format("Hallo\n") always inserts a Linux line pause regardless of the operating system. public class LineBreaks { public static void main(String[] args) { System.out.println(String.format("Hallo%northward").length()); System.out.println(String.format("Hallon").length()); } } Organization.lineSeparator(). Path names
C:\Users\sven\.m2\settings.xml /domicile/sven/.m2/settings.xml File. separator constant or the FileSystems.getDefault().getSeparator() method.coffee.io.File and, starting with Coffee 7, java.nio.file.Path to construct directory and file paths without having to specify the separator. Summary and outlook
File, Path, and Paths DataOutputStream and DataInputStream
Source: https://www.happycoders.eu/java/how-to-read-files-easily-and-fast/
0 Response to "How Fast a Bufferedreader Reader Read File"
Enregistrer un commentaire